

The digital world is ever-evolving and as it evolves, so does Google. With new updates from artificial intelligence, we’ll dive into the nuances behind Google SMITH vs BERT and the future of natural language processing.
Google continuously makes changes in the way it displays results to you. If you look at the Google algorithm change history, you will notice that each important update it makes is designed to help improve user experience and ensure better-optimized search results.
On that note, Google recently introduced a new algorithm, namely Google SMITH by publishing a research paper on it. The paper claims the new algorithm is superior to BERT for understanding long-form documents. If you’re searching for Google SMITH vs BERT, your search ends here.
Google SMITH is a new algorithm model that enables Google to understand entire documents rather than just brief sentences and paragraphs. BERT is designed to understand words within the context of sentences.
SMITH is the short form for Siamese Multi-Depth Transformer-Based Hierarchical Encoder. This algorithm model has been trained to understand long-form documents, and blocks of sentences within the context of the entire document.
Algorithms like BERT train on data sets to predict that randomly hidden words are from the context within sentences. On the other hand, the SMITH algorithm is trained to predict the next block of sentences. It’s for that reason that researchers say that SMITH is able to understand larger documents better than BERT.
Language plays a crucial role for SMITH to understand the content and also to help users get the right thing. When it comes to search, the Google algorithm must process the nuance of languages and dialects to serve results instantly, which is why this language training is crucial for NLPs. Google performs thorough research on language understanding and Natural Language Processing (NLP) in the form of input and model training.
Google hasn’t said what specific algorithm it is using. However, according to researchers SMITH is better than BERT, but since Google has not formally declared that the SMITH algorithm is in use to understand passages in the web pages, whether it’s in use or not remains purely speculative
Google BERT was launched back in October 2019 and has been quite useful, but it’s not trained for understanding the long-form documents and block of sentences.
BERT stands for Bidirectional Encoder Representations and Transformers. It’s has done so well in assisting the search software to understand documents in order to rank them based on a specific query.
BERT models are able to analyze the full context of a word by looking at the words that come before and after it. This way BERT models can understand the intent behind search queries.
While it has been performing well, it has a limitation: BERT can only handle a few sentences or an entire paragraph.
BERT is trained to process short documents or predict the next words in a sequence to provide accurate results. BERT is not good for understanding long-form documents. It’s for this reason that Google is looking at SMITH.
The longer the document is, the better SMITH performs at understanding it.
As previously mentioned, BERT is trained to understand short documents. It’s not suitable for long-form documents. On the other hand, SMITH can grasp blocks of sentences or passages within the context of an entire document.
While SMITH can do something that BERT is unable to do, it doesn’t replace BERT. Instead, the SMITH model will be used to supplement BERT in order to work together to fully understand the content of a document.
The SMITH algorithm can help with long-tail queries. However, according to research the issue of matching long queries to long-form documents has not been explored sufficiently. This is the exact problem that the researchers are solving with SMITH.
To understand how Google SMITH can match passages within the context of a long-form document, it’s important to understand the concept of algorithm pre-training.
Algorithm pre-training is the concept of training an algorithm on a specific data set. During this exercise, the engineers mask or hide random words within sentences, and then the algorithm will try to predict the masked words.
For example, if a sentence is written as: “KFC was founded by ____,” the algorithm when fully trained might predict Colonel Sanders comes next.
This process is repeated over and over again with different phrases and sentences until the algorithm can provide the right thing, or in other words, becomes fairly smart.
The algorithm will learn through the training and eventually become optimized to become accurate and make fewer mistakes. That’s the sole purpose of the pre-training.
In the document published by Google, researchers explain a key part of the SMITH algorithm – How the algorithm can use the relations between sentence blocks to understand the entire document in the pre-training process.
When it comes to BERT, the pre-training involves the prediction of the masked word. SMITH involves the prediction of the masked sentence. That’s what makes the SMTH algorithm better than the BERT algorithm.
So, in the pre-training, researchers go beyond masked word prediction to masked sentence prediction. The training involves masking out blocks sentences in a document so that it can predict them accurately and with fewer mistakes when it’s fully trained.
During the training process, the algorithm learns the relationship between words and then learns the context of the blocks of sentences and how they relate to each other in a long-form document. The algorithm can identify the next block of sentences in a long-form document.
In the conclusion of the research paper, it was stated that the SMITH algorithm performs better than BERT for longer input documents.
Google SMITH is a new algorithm model that enables Google to understand entire documents rather than just brief sentences and paragraphs. BERT is designed to understand words within the context of sentences.
SMITH stands for Siamese Multi-Depth Transformer-Based Hierarchical Encoder. This algorithm model has been trained to understand long-form documents, and blocks of sentences within the context of the entire document.
Algorithms like BERT are trained on data sets to predict that randomly hidden words are from the context within sentences. On the other hand, the SMITH algorithm is trained to predict the next block of sentences. It’s for that reason that researchers say that SMITH is able to understand larger documents better than BERT.
Language plays a crucial role for SMITH to understand the content and also to help users get the right thing. When it comes toSEO, users speak several languages, and thus it becomes hard for Google to figure out every stuff and display the results that match every query in milliseconds. This is why Google requires thorough research on language understanding and Natural Language Processing (NLP).
Google hasn’t said what specific algorithm it is using. However, according to researchers SMITH is better than BERT, but since Google has not formally declared that the SMITH algorithm is in use to understand passages in the web pages, whether it’s in use or not remains purely speculative.
Google BERT launched back in October 2019 and has been quite useful, but it’s not trained for understanding the long-form documents and block of sentences.
BERT stands for Bidirectional Encoder Representations and Transformers. It’s has done so well in assisting the search software to understand documents in order to rank them based on a specific query.
The various BERT models are able to analyze the full context of a word by looking at the words that come before and after it. This way BERT models can understand the intent behind search queries.
While it has been performing well, it has its limitations. The Bidirectional Encoder Representations and Transformers algorithm can only handle a few sentences or an entire paragraph.
BERT is trained to process short documents or predict the next words to provide accurate results. BERT is not good for understanding long-form documents. It’s for this reason that Google is looking at SMITH.
The longer the document is, the better SMITH performs at understanding it.
As previously mentioned, BERT is trained to understand short documents. It’s not suitable for long-form documents. On the other hand, SMITH can grasp blocks of sentences or passages within the context of an entire document.
While SMITH can do something that BERT is unable to do, it doesn’t replace BERT. Instead, the SMITH model will be used to supplement BERT in order to work together to fully understand the content of a document.
The SMITH algorithm can help with long-tail queries. However, research indicates the issue of matching long queries to long-form documents has not been explored sufficiently. This is the exact problem that the researchers are solving with Google SMITH vs BERT.
To understand how Google SMITH can match passages within the context of a long-form document, it’s important to understand the concept of algorithm pre-training.
Algorithm pre-training is the concept of training an algorithm on a specific data set. During this exercise, the engineers mask or hide random words within sentences, and then the algorithm will try to predict the masked words.
For example, if a sentence is written as: “KFC was founded by ____,” the algorithm when fully trained might predict Colonel Sanders comes next.
This process is repeated multiple times with different phrases and sentences until the algorithm can provide the right thing, or in other words, becomes fairly smart.
The algorithm will learn through the training and optimizes itself for accuracy, which results in fewer mistakes. That’s the sole purpose of pre-training.
In the document published by Google, researchers explain a key part of the SMITH algorithm – How the algorithm can use the relations between sentence blocks to understand the entire document in the pre-training process.
When it comes to Google SMITH vs BERT, the pre-training involves the prediction of the masked word. SMITH involves the prediction of the masked sentence. A masked sentence represents the hidden sentence in a passage. SMITH is able to predict the whole missing masked phrase as opposed to one word. That’s what makes the SMITH algorithm better than the BERT algorithm.
So, in the pre-training, researchers go beyond masked word prediction to masked sentence prediction. The training involves masking out blocks sentences in a document so that it can predict them accurately and with fewer mistakes when it’s fully trained.
During the training process, the algorithm learns the relationship between words. Then the algorithm learns the context of the blocks of sentences and how they relate to each other in a long-form document. The algorithm can identify the next block of sentences in a long-form document.
In the conclusion of the research paper, it was stated that the SMITH algorithm performs better than BERT for longer input documents.
The standard definition of an algorithm is a set of rules for calculations or problem solving, especially by a computer. A Google algorithm also follows the same definition.
Therefore, Google has a complex system that retrieves data from the search index to instantly deliver search results. Google does not use a single algorithm but a combination of algorithms to deliver accurate results. Webpages are ranked by relevance on search engine results pages.
There are numerous changes to Google’s algorithms every year. More often than not updates go unnoticed because they are slight adjustments. Occasionally, Google releases updates to the algorithms that significantly impact the search engine results pages (SERPs). These algorithms also include content and local SEO components as well.
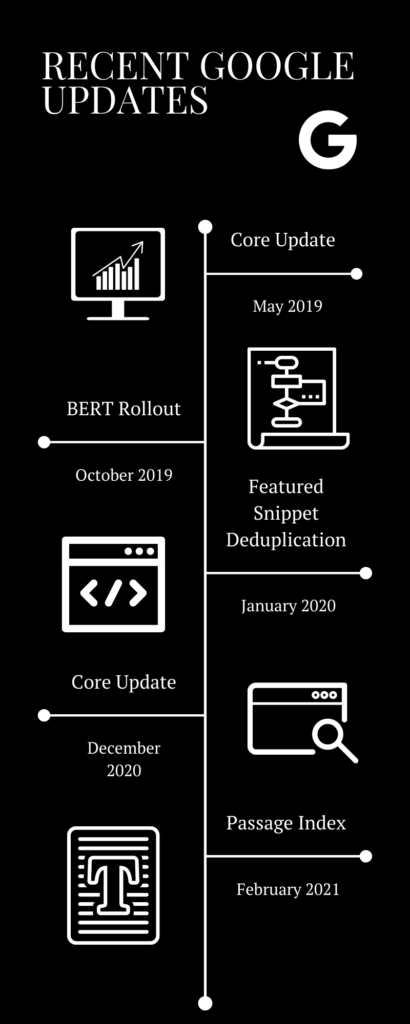
Announced on Twitter by Danny Sullivan of Google.

Noticed by SEOs in the first week of December. This algorithm update was observed by SearchEngineLand.
This was announced on Twitter by Google Search Liaison Danny Sullivan that they would be releasing a broad core algorithm update.
Confirmed by Google that webpages in a featured snippet position would not be repeated in regular Page 1 organic listing. The change affected all search listings worldwide.
This was announced on Twitter that a broad core algorithm update would be released.
The beginning of the worldwide rollout of BERT was announced on Twitter, and it included numerous languages.
The first BERT Update was described as the biggest change to Google search in the past 5 years. BERT models assist Google in understanding search queries. The change affected both search rankings and featured snippets and BERT.
This was announced via Twitter and was released within a few hours.
New broad core algorithm update.
In conclusion, when comparing Google SMITH vs BERT, SMITH is better than BERT at understanding longer text inputs. The deployment of Google SMITH intrigues members of the search community. Since Google has not formally stated they are using SMITH, we can know for sure if it’s a part of the ranking algorithm.
The research confidently states SMITH outperforms all the other models for understanding long-form documents. And it does not state that more research is needed. Researchers are confident in the SMITH test results. Google will make its own decision as to whether to use the algorithm alongside BERT. Experts, specifically those who have seen the research paper would be surprised if SMITH is not in use in the near future or currently being tested.